字符串 - KMP
KMP
KMP 算法可以用 的复杂度在一个字符串中匹配子串。要理解 KMP 算法的原理,需要首先用暴力算法写一个匹配字符串的方法,如下:
1 | // s: 母串, p: 模板串 |
这种做法不好的地方在于它没有充分利用已知条件,做出很多重复的判断,而 KMP 算法就是利用模板串中的特点来减少重复判断。
原理是将模板串中任意一个地方的 s[i] 都预先找到一个数值 n = next[i],意思是到 i 位置的字符串为止相同前缀后缀的长度,即 s[~n] == s[i-n~i],如下图所示:
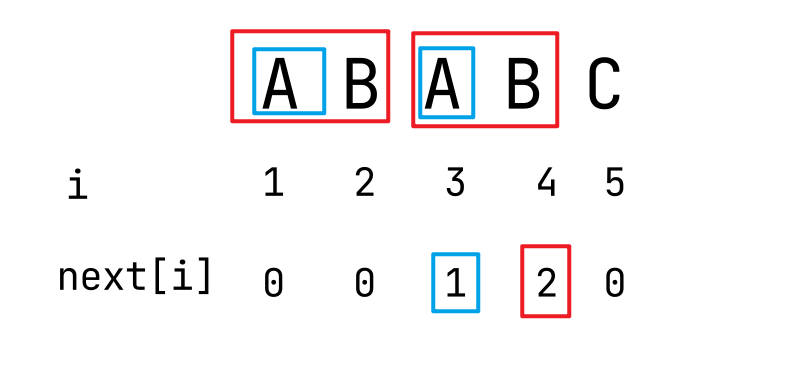
匹配
先跳过如何构造 next 数组,我们来关注如何匹配子串。
因为对于子串 中每一个 j 都有一个 next[j] 前面的部分相等,所以当一位匹配失败时就可以退回到 next[j-1]继续匹配,直到无路可退(即退到 0)。为了使代码更加好写,这里通常将 ,而母串 中是 。
1 |
|
注意我们这里的下标都是从 1 开始的,这样可以省去很多不必要的麻烦。
总结这三个步骤:
- 检测是否能够回退
j并且回退直到无法回退,包含j已退到开头和当前位置匹配成功两种情况。 - 如果当前位置(
i与j+1)匹配成功,将j后移一位。 - 检测是否匹配结束,并且将
j回退一次接着匹配下一个。
next 数组
构造 next 数组的过程就是一个匹配的过程,所以大体代码与上文类似。
1 | ne[1] = 0; |
注意,这里一定要从 2 开始循环,因为 j 为 0 时如果从 1 开始就会导致 p[i] == p[j+1],从而构建错误的 next 数组。其次,next[1] = 0 是一定的。
用两张图来演示这一过程,首先是第一次匹配时:

其次是匹配失败时回退的情况:
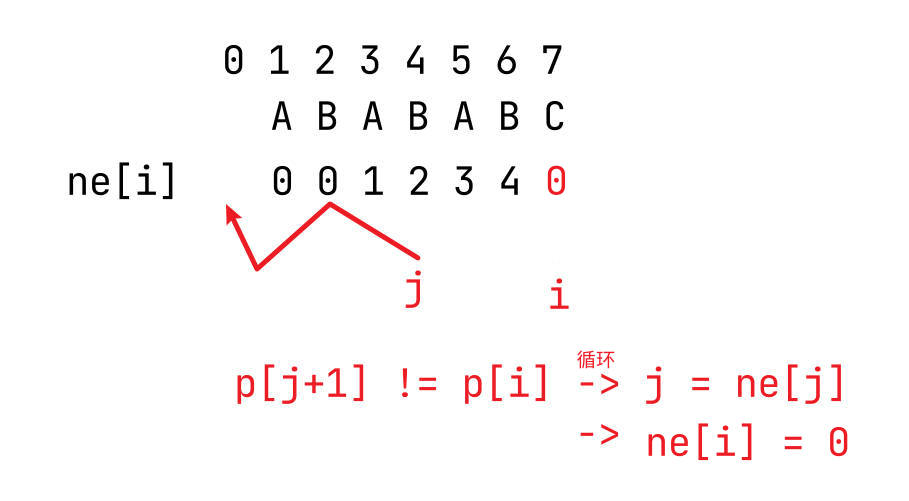
小结
KMP 算法通过将相同前缀后缀的长度储存到 next 数组中来避免匹配时重复操作,将 的暴力算法优化到了 复杂度。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 喵喵小窝!